


最近在抽空读徐鸿鹄老师新书《统计信仰》,写一写读书笔记。

===
在算法领域的NFL重要原则:脱离具体问题或场景,空谈哪种算法更好毫无意义。
1912年Fisher正式提出极大似然估计。如何理解极大似然估计,《统计信仰》给出一个案例:假设有一枚图钉,设p为随机投掷后图钉尖朝上的概率,现求p。现投掷5次,尖朝上的结果为上、下、上、上、下。在实验互不影响的前提下,尖朝上顺序出现的概率y可以写成y=p^3(1-p)^2。这个方程被称作似然函数,画出它的图像,能够轻易捕捉到似然函数有一个局部极大值点。通过数值求解可知,当p=0.6时,似然函数取到局部极大值。
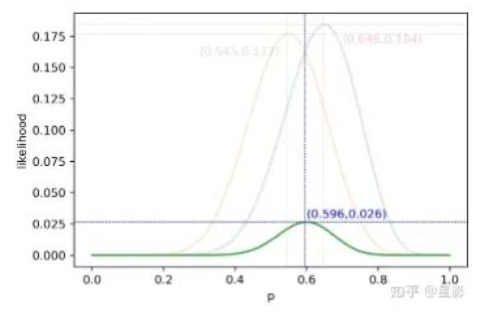
图:知乎星影
这种将p的估计值设定为一个值,使得y到局部极大值的基本思想就是极大似然估计。
===
大样本和小样本的差别本质不在于样本量的大小,而在于样本量N是趋于无穷大,还是固定在某个值上。
在专著《The Design of Experiments》中,Fisher第一次提出显著性检验的概念。到1928年,J.Neyman和E.S.Pearson完善了显著性检验,完整提出建设检验,也被称为Neyman-Pearson理论(N-P理论)。
犯第一类错误和第二类错误之间是此消彼长的关系,必须作出取舍。最佳选择应使得两者之间达到最佳平滑。最普遍的做法是将犯第一类错误的概率限定在常用显著性水平α上,比如0.05,以此来优先保证犯第一类错误的概率很低。
N-P理论有一个原则:要求优先限定犯第一类错误的概率,在这个基础上,使得犯第二类错误的概率尽可能小。举例:带上一把无用的雨伞在外面溜达总好过在倾盆大雨里狂奔。
优先限定犯第一类错误的概率是一个更加理性的选择。
===
我们经常要求p值小于0.05,就是为了把犯第一类错误的概率控制0.05之内。
对于原假设H0来说,如果结果显著,结论就可以被推翻;如果结果不显著,得到的最好结论就只是“无法推翻原假设”,而不是“接受原假设”,无法推翻与接受是两个不同的概念。对H0就两个结论,要么直接被否定,要么证据不足无法否定它。
===
棣莫弗第一个推导出正态分布的概率密度函数,拉普拉斯则在《分析概率论》中进行了拓展,并最终建立了中心极限定理的一般形式。但注意,18世纪出现的正态分布最终被冠以19世纪才出生的高斯的名号。
根据中心极限定理,随机误差服从正态分布。高斯分布成为统计系核心理论。
===
样本x作为随机变量,有自己的概率分布,叫做样本分布,比如泊松分布、正态分布;样本抽样后的统计量作为样本的已知函数,也有自己的概率分布,即统计量的概率分布,它不同于样本分布,叫做抽样分布,比如卡方分布,t分布,F分布。
===
一般线性模型统一了定量和分类的自变量,但因变量却还只是连续型的。统计学家无法容忍这瑕疵,所以尝试继续泛化,于是诞生了广义线性模型。
广义线性模型的作用其实就是处理回归问题。
===
频率观点通常包括连续性假设,连续性假设意味着一切规律都能稳定和永久地运行,不会有意外事件发生打破这个规则。
但实际上,没有严格一致的平行宇宙供人们一次又一次得展开相同的实验,因此很难研究其客观规律。
在频率派学者看来,频率是观察到的历史情况,概率是要建立的模型。单纯对频率的信仰并不能帮助我们选择合适的 算法来解决实际问题。
以上文字均来自:徐鸿鹄《统计信仰》。
本文不标记原创,如有侵犯知识,请告知删除。
===
我的其他读书笔记:
动动你的小手,关注我的公众号:
目前我在微信公众号、知乎、博客上持续发布统计分析文章,读者可以从搜索引擎找到我,也欢迎直接订阅关注我的公众号。
SPSS统计咨询公众号

↑↑↑专门解决SPSS数据分析难题,已发布《学不会SPSS就来答疑突破》《问卷分析三剑客》等畅销视频教程。作者数据小兵,欢迎关注,一起学用SPSS。
数据小兵公众号

数据小兵,统计学知识博主,长期从事统计软件应用研究与数据分析工作。
JASP统计分析公众号

探索和使用免费开放的全新统计软件JASP,主理人数据小兵。